
Avant de commencer l'article, examinons la terminologie :
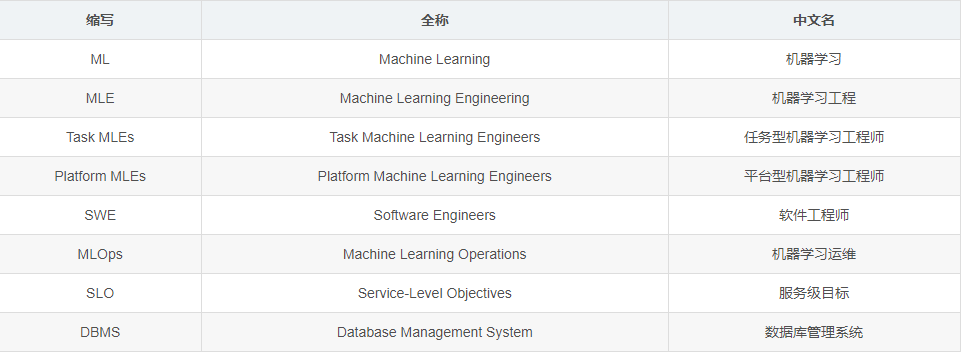
Automatiser le cycle de vie de l' apprentissage automatique (ML) de bout en bout, même pour une tâche de prédiction spécifique, n'est ni facile ni simple. Les gens ont dit que l'ingénierie de l'apprentissage automatique (MLE) était un sous-ensemble de l'ingénierie logicielle, ou devrait être traitée comme telle. Mais au cours des 15 derniers mois en tant que doctorant, j'ai pensé à MLE à travers une lentille d'ingénierie de données.

Ingénieur en machine learning basé sur les tâches
Il existe deux types d'ingénieurs en apprentissage automatique (MLE) critiques pour l'entreprise. Les premiers sont les Task Machine Learning Engineers (Task MLE), qui sont chargés de maintenir un pipeline ML spécifique (ou un petit ensemble de pipelines ML) en production. Ils se concentrent sur des modèles spécifiques pour les tâches critiques de l'entreprise. Ce sont eux qui sont appelés lorsque l'indicateur de la ligne supérieure baisse et sont chargés de "réparer" quelque chose. Ce sont eux qui sont les plus susceptibles de vous dire quand un modèle a été réentrainé pour la dernière fois, comment il a été évalué, etc.
Les MLE de tâche ont trop à faire. Les data scientists prototypent des modèles et proposent des idées fonctionnelles, tandis que les Task MLE doivent les « produire ». Cela nécessite d'écrire des pipelines qui transforment les données en entrées de modèle, entraînent et recyclent le modèle, évaluent le modèle et génèrent les prédictions quelque part. Ensuite, les MLE de tâche doivent être responsables du déploiement, ce qui nécessite généralement un processus par étapes comprenant les tests, la mise en service, etc. Les MLE de tâche doivent ensuite effectuer une "surveillance" pour diagnostiquer et répondre rapidement aux erreurs liées au ML.
J'étais un Task MLE. J'ai fait toutes ces choses et c'était terrible. Lorsque j'ai quitté l'entreprise pour mon doctorat et mon transfert de poste, il m'a fallu environ un mois pour créer des notes détaillées détaillant le fonctionnement du cycle de vie ML de bout en bout . Lors de la rédaction de la documentation, je me demande souvent pourquoi je fais cela à ce moment-là, par exemple pourquoi lorsque le modèle est recyclé, l'ensemble d'entraînement est automatiquement actualisé, mais l'ensemble d'évaluation reste le même, ce qui m'oblige à l'actualiser manuellement ? Je n'ai jamais voulu être scientifiquement laxiste, mais j'ai souvent rencontré du code expérimental dans mon propre processus de développement de modèle où les hypothèses formulées lors de la formation du modèle n'ont pas tenu pendant la phase d'évaluation, et encore moins après la mise en service du déploiement.
Parfois, je deviens tellement scientifique que l'entreprise perd de l'argent. J'automatise une procédure de réglage d'hyperparamètres qui divise les ensembles d'entraînement et de validation en plusieurs plis en fonction du temps (validation croisée multiple) et sélectionne les hyperparamètres qui fonctionnent le mieux en moyenne sur tous les ensembles. Je n'ai réalisé qu'après coup à quel point c'était stupide. Je dois choisir les hyperparamètres qui produisent le meilleur modèle dans le dernier ensemble d'évaluation.
J'ai fait suffisamment de recherches sur Production ML maintenant pour savoir que le simple fait de sur-adapter les dernières données et de le recycler constamment est une petite astuce utile pour améliorer les performances du modèle. Les entreprises qui réussissent le font.
Je suis confus quand les gens disent que les petites entreprises ne peuvent pas se recycler tous les jours parce qu'elles n'ont pas les budgets des géants comme FAANG (c'est-à-dire Facebook, Amazon, Apple, Netflix, Google). Le recyclage de nombreux modèles xgboost ou scikit-learn peut coûter quelques dollars tout au plus. La plupart des modèles ne sont pas de grands modèles de langage. J'ai appris ce moyen détourné en faisant des recherches sur la surveillance du ML. J'ai demandé aux Task MLE de nombreuses petites entreprises si et comment ils surveillaient les changements de distribution dans leurs pipelines, et la plupart d'entre eux mentionnent des horaires de recyclage horaires, quotidiens ou hebdomadaires.
"Je sais que cela ne résout pas vraiment le problème de la dérive des données", m'a dit un jour un MLE de tâche timidement, comme s'il avait avoué un secret qu'il avait peur d'écrire dans une évaluation des performances.
"Les performances du modèle ont-elles augmenté?", ai-je demandé.
"Eh bien, oui..." dit-il d'une longue voix.
"Ensuite, il s'agit de résoudre le problème de la dérive des données", dis-je d'un ton neutre, avec une confiance en soi gonflée en tant que chercheur.
Des anecdotes comme celle-ci m'ont vraiment bouleversé. Je suppose que c'est à cause de ce que je pensais être des questions importantes et intéressantes, et maintenant il ne reste plus que des questions intéressantes. Les chercheurs considéraient le changement de distribution comme très important, mais les problèmes de performances du modèle résultant du changement de distribution naturel ont soudainement disparu après le recyclage.
J'ai du mal à trouver des faits utiles dans la dérive des données, le vrai problème. Cela semble évident maintenant : des problèmes de données et d'ingénierie (des cas de dérive soudaine) ont déclenché une dégradation des performances du modèle. Il est possible que le travail d'hier consistant à générer les fonctionnalités contextuelles ait échoué, nous ne pouvons donc utiliser que les anciennes fonctionnalités contextuelles. Il est possible qu'une source de données ait été corrompue, de sorte qu'un tas de fonctionnalités sont devenues nulles. Cela pourrait être ainsi, cela pourrait être ainsi, mais le résultat final est le même : les données semblent différentes, le modèle est sous-performant et les mesures commerciales en souffrent.

Ingénieur Plateforme Machine Learning
C'est maintenant le bon moment pour introduire un deuxième type d'ingénieur en apprentissage automatique : les Platform MLE, qui aident les Task MLE à automatiser les parties fastidieuses de leur travail. Les MLE de plate-forme créent des pipelines (y compris des modèles) qui prennent en charge plusieurs tâches, tandis que les MLE de tâche résolvent des tâches spécifiques. Ceci est similaire, dans le monde des ingénieurs logiciels, à la construction d'infrastructures par rapport à la construction de logiciels au-dessus de l'infrastructure. Mais je les appelle Platform MLE, et non Platform SWE, car je ne pense pas qu'il soit possible d'automatiser entièrement le ML sans en savoir suffisamment sur le ML.
Le besoin de plates-formes MLE se matérialise lorsqu'une organisation dispose de plusieurs pipelines ML. Voici quelques exemples des différences entre les MLE de plate-forme et les MLE de tâche :
-
Les MLE de plate-forme sont responsables de la création de pipelines de fonctions ; les MLE de tâches sont responsables de l'utilisation des pipelines de fonctions ;
-
Les MLE de plate-forme sont responsables de la formation du cadre du modèle ; Les MLE de tâche sont responsables de l'écriture des fichiers de configuration correspondants pour l'architecture du modèle et le plan de recyclage ;
-
Les MLE de plate-forme sont responsables du déclenchement des alertes de dégradation des performances ML ; les MLE de tâche sont responsables de la prise de mesures sur les alertes.
Les MLE de tâche ne sont pas réservées aux entreprises qui aspirent à l'échelle FAANG. Ils existent généralement dans toute entreprise avec plus d'une tâche de ML. C'est pourquoi, je pense, les opérations d'apprentissage automatique (MLOps) sont actuellement supposées être un segment très lucratif. Chaque entreprise de ML a besoin de fonctionnalités, de surveillance, d'observabilité, etc. Mais pour les plates-formes MLE, il est plus facile de créer vous-même la plupart des services : (1) écrivez un pipeline qui actualise quotidiennement la table des fonctionnalités ; (2) utilisez des journaux normalisés sur tous les outils ML ; (3) enregistrez les versions des informations des ensembles de données. Ironiquement, les startups MLOps tentent de remplacer les Platform MLE par des services payants, mais elles demandent aux Platform MLE d'intégrer ces services dans leurs entreprises.
En tant que spectateurs, certaines sociétés MLOps ont essayé de vendre des services aux Task MLE, mais les Task MLE étaient trop occupées à s'occuper des modèles pour passer par le cycle de vente. S'occuper d'un modèle est un travail difficile qui demande beaucoup de concentration et d'attention. J'espère que cette situation changera à l'avenir.
Pour le moment, les responsabilités de Platform MLE qui m'intéressent le plus sont la surveillance et le débogage des problèmes soudains de dérive des données. Les MLE de plate-forme ont la limitation qu'ils ne peuvent rien changer en rapport avec le modèle (y compris les entrées ou les sorties), mais ils sont responsables de savoir quand et comment ils sont cassés. Des solutions de pointe surveillent la couverture (c'est-à-dire les parties manquantes) et la distribution des caractéristiques individuelles (c'est-à-dire les entrées) et les sorties du modèle au fil du temps. C'est ce qu'on appelle la validation des données. Les plateformes MLE déclenchent des alertes lorsque ces changements dépassent un certain seuil (par exemple, une baisse de couverture de 25 %).
La validation des données permet d'obtenir un rappel énorme. Je parierais qu'au moins 95 % des dérives soudaines, principalement causées par des problèmes d'ingénierie, sont détectées par des alertes de validation des données. Cependant, sa précision est médiocre (je parie moins de 20% pour la plupart des tâches) et il nécessite une tâche MLEs pour énumérer toutes les fonctionnalités et les seuils de sortie. En pratique, la précision peut être inférieure car les MLE de tâche souffrent de la fatigue des alarmes et coupent la plupart des alarmes.
Pouvons-nous troquer la précision contre le rappel ? La réponse est non, car un rappel élevé est tout l'intérêt d'un système de surveillance. Pour attraper des bogues.
Devez-vous surveiller chaque fonction et chaque sortie ? Non, mais les alertes doivent être au niveau d'une colonne, sinon elles seront inopérantes pour les tâches MLE. Dire que le composant PCA #4 dérive de 0,1 par exemple est inutile.
Pouvez-vous ignorer ces alertes en déclenchant un recyclage ? Non, il n'y a aucune valeur à recycler sur des données invalides.
Pendant un certain temps, j'ai pensé que la validation des données était un proxy pour la surveillance des métriques ML telles que l'exactitude, la précision, le rappel. En raison du manque de véritables étiquettes pour les données, la surveillance des métriques ML est presque impossible à effectuer en temps réel. De nombreuses organisations ne reçoivent des balises que sur une base hebdomadaire ou mensuelle, ce qui est trop lent. De plus, toutes les données n'ont pas d'étiquettes. Il ne reste donc plus qu'à surveiller l'entrée et la sortie du modèle, c'est pourquoi tout le monde surveille l'entrée et la sortie.
Je ne pouvais pas avoir plus tort. En supposant que les MLE de tâche aient la capacité de surveiller les métriques de ML en temps réel, la validation des données est toujours utile à ce stade pour les raisons suivantes :
-
Tout d'abord, des modèles pour différentes tâches peuvent être lus à partir des mêmes entités. Plusieurs MLE de tâche peuvent bénéficier si un seul MLE de plate-forme peut correctement déclencher une alerte de corruption de fonctionnalité.
-
Deuxièmement, à l'ère des piles de données modernes, les fonctionnalités et les sorties des modèles (c'est-à-dire le stockage des fonctionnalités) sont souvent utilisées par les analystes de données, de sorte que l'exactitude des données doit être garantie. Une fois, j'ai parcouru un tas de requêtes dans Snowflake sans réaliser que la moitié d'une colonne liée à l'âge était négative, et j'ai présenté sans vergogne cette information à un PDG.
J'ai appris qu'il n'y a rien de mal à faire ce genre d'erreur. Le Big Data peut vous aider à raconter n'importe quelle histoire, bonne ou mauvaise. La seule chose qui compte est que vous teniez fermement à vos opinions erronées, sinon les gens douteront de vos capacités. Personne d'autre ne passera en revue vos techniques d'utilisation des trames de données Pandas dans Untitled1.ipynb. Ils ne sauront pas que vous avez merdé.
J'espère que le paragraphe ci-dessus est un mensonge. Je ne plaisante qu'à moitié.

d'autres pensées
Le besoin d'assurance de la qualité des données et des modèles ML (c'est-à-dire les objectifs de niveau de service, ou SLO en abrégé) m'a amené au cœur de ma première année de recherche : le rôle des MLE, qu'ils soient basés sur des tâches ou sur des plateformes, pour assurez-vous que ce SLO est satisfait. Cela me rappelle l'ingénierie des données plus que tout autre rôle. En termes simples, les ingénieurs de données sont chargés d'exposer les données aux autres employés ; les ingénieurs ML sont chargés de s'assurer que ces données et les applications qui les accompagnent (telles que les modèles ML) ne sont pas des ordures.
Je pense beaucoup à ce que signifie avoir une bonne qualité de modèle. Je déteste le mot qualité. C'est un terme vaguement défini, mais la réalité est que chaque organisation a une définition différente. Beaucoup de gens pensent que la qualité signifie "pas obsolète", ou s'assurer que le pipeline de génération de fonctionnalités fonctionne avec succès à chaque fois. C'est un bon début, mais peut-être devrions-nous faire mieux.
Dans la perspective SLO des données, la validation des données est un concept réussi car elle définit explicitement la qualité de chaque entrée et sortie du modèle de manière binaire. Soit au moins la moitié des fonctionnalités sont manquantes, soit aucune. Soit l'âge est un nombre positif, soit il ne l'est pas. Soit l'enregistrement est conforme à un modèle prédéfini, soit il ne l'est pas. Respectez ou non le SLO.
Supposons que chaque organisation puisse clairement définir ses SLO de qualité des données et des modèles. Dans un environnement ML, où devons-nous valider les données ? Traditionnellement, les règles centrées sur les données étaient appliquées par le SGBD. Dans son article présentant la base de données Postgres, Stonebraker a expliqué succinctement la nécessité pour la base de données d'appliquer des règles : Les règles sont difficiles à appliquer au niveau de la couche application car les applications ont souvent besoin d'accéder à plus de données que les transactions n'en ont besoin. Par exemple, l'article mentionne une base de données d'employés dont les règles sont que Joe et Fred doivent avoir le même salaire ; plutôt que de demander à l'application le salaire de Joe et Fred et d'affirmer l'égalité chaque fois que le salaire de Joe ou Fred est nécessaire, il est préférable de utiliser les données imposées dans le gestionnaire.
Il y a un an, mon mentor m'a dit la phrase « Des contraintes et des déclencheurs sont nécessaires pour maintenir les pipelines ML en bonne santé », et je m'en suis souvenue même si je ne comprenais pas tout à fait ce que cela signifiait. En tant que MLE pré-tâche, je pense que cela signifie utiliser du code pour enregistrer la moyenne, la médiane et l'agrégation de diverses entrées et sorties, et lancer des erreurs lorsque les vérifications de validation des données échouent, ce que je fais au travail.
Maintenant que j'ai plus d'expérience avec les Platform MLE, je ne pense pas que les Task MLE devraient faire ces choses. Les MLE de plate-forme ont des capacités de gestion des données, tandis que les MLE de tâche ont des capacités d'application ou sont responsables de la partie aval du pipeline ML. Les MLE de plate-forme doivent appliquer des règles (par exemple, la validation des données) dans la table des fonctionnalités afin que les MLE de tâche soient alertés de toute erreur lors de l'interrogation. Les MLE de plate-forme doivent exécuter des déclencheurs comme les divers MLE de tâche de post-traitement ad hoc sur les prévisions avant de les présenter aux clients.
J'ai aussi beaucoup réfléchi à la manière de faciliter la compréhension de la "qualité du modèle" par les gens. Une définition spécifique à l'organisation de la qualité du modèle permet d'expliquer pourquoi les entreprises de ML ont leurs propres frameworks de ML de production (par exemple, TFX), certains open source et d'autres fermés. De nombreux nouveaux frameworks font leur apparition dans le cadre des startups MLOps.
J'avais l'habitude de penser que la raison pour laquelle les gens ne passaient pas à un nouveau framework était que réécrire tout le code de plomberie serait lourd, c'est vrai, mais l'écosystème webdev est un contre-exemple : si les gens en profitent, ils réécrivent le code . La seule différence est que les frameworks de pipeline ML actuels sont rarement autonomes et ne peuvent pas être facilement connectés à divers backends de gestion de données.
Le cadre du pipeline ML doit être étroitement couplé au SGBD qui comprend la charge de travail ML, le SGBD doit savoir quel type de déclencheurs veulent les MLE de tâche, comprendre la validation des données et régler les alertes pour avoir une bonne précision et rappel, et garantir une certaine évolutivité sexe . C'est peut-être pour cette raison que beaucoup de personnes à qui j'ai parlé récemment semblent se tourner vers Vertex AI (un service de type base de données qui peut tout faire).
C'est bizarre de faire des recherches sur tout ça. Ce n'est pas comme beaucoup de doctorats de mes amis, où je suis censé poser une série de questions scientifiques et mener un tas d'expériences pour arriver à une conclusion. Ma thèse de doctorat ressemble plus à une exploration où j'étudie le fonctionnement de la gestion des données, deviens un historien du métier et essaie de faire un point sur la façon dont cela se déroulera dans l'écosystème MLE. Cela semble être une théorie fondée et je mets constamment à jour mes opinions en fonction des nouvelles informations que j'apprends.
Pour être honnête, c'est inconfortable d'avoir l'impression de changer d'avis si souvent ; je ne sais pas exactement comment le décrire. Une personne proche de moi m'a dit que c'est la nature de la recherche. Nous ne connaissons pas toutes les réponses, encore moins les questions, en premier lieu, mais nous allons développer un processus pour les découvrir. Cependant, pour des raisons de santé mentale, j'ai hâte de changer moins d'avis sur Production ML.
- Lecture recommandée -
" Nouveau programmeur 001-004 " a été entièrement répertorié
Scannez le code QR ci-dessous ou cliquez pour vous abonner maintenant
