Réimprimé avec la permission de Big Data Digest de Data Pi THU
Auteurs : Even Oldridge, Karl Byleen-Higley
Traduction : Chen Zhiyan
Relecture : zrx
Le plus grand défi auquel les novices sont confrontés lors de la création de systèmes de recommandation est le manque de compréhension tangible des systèmes de recommandation, concentrant la plupart du contenu en ligne des systèmes de recommandation sur des modèles, et souvent limité à un simple exemple de filtrage collaboratif. Pour les nouveaux praticiens, il existe un énorme fossé entre les exemples modèles simples de systèmes de recommandation et les systèmes de production réels.
Ce blog partagera avec les lecteurs un modèle qui couvre l'ensemble du processus de déploiement d'un système de recommandation, avec des exemples de programmes d'entreprises telles que Meta, Netflix et Pintery. Ce modèle est la technologie de base de l'équipe NVIDIA Merlin pour construire un système de bout en bout, et nous sommes heureux de le partager et de le promouvoir dans la communauté pour aider les lecteurs à construire le concept et le consensus du déploiement de systèmes de recommandation (pas seulement des modèles) . Si vous êtes intéressé par le contenu dans ce domaine, vous pouvez également assister à un discours d'ouverture organisé par l'atelier Industrial Recommender Systems de KDD.
Modèle de recommandation de regarder ailleurs
Ce qu'un modèle de recommandation fait, qu'il s'agisse d'un simple exemple de filtrage collaboratif ou d'un modèle d'apprentissage en profondeur comme DLRM, est essentiellement un classement, ou plus précisément, un système de notation où les utilisateurs sont intéressés par un ensemble de notations d'éléments de données. Cependant, ces scores en eux-mêmes sont souvent insuffisants pour fournir des recommandations raisonnables aux utilisateurs dans le monde réel. Avant d'explorer les solutions et de construire le système de recommandation final, les raisons suivantes seront étudiées en profondeur.
Plus il y a d'éléments de données
Le premier problème rencontré en premier est le nombre d'éléments de données dans la recommandation. Dans les cas extrêmes, les enregistrements d'éléments de données peuvent représenter des millions, des centaines de millions ou même des milliards. Dans la plupart des cas, la notation de chaque élément de données n'est pas réalisable et la notation est d'un coût prohibitif. En pratique, vous devez d'abord sélectionner rapidement un sous-ensemble pertinent de ces éléments, comme la notation de mille ou dix mille éléments de données.
En entrant dans la deuxième étape, avant de noter les éléments de données, il est nécessaire de sélectionner un ensemble raisonnablement pertinent contenant des éléments de données auxquels les utilisateurs participeront éventuellement. Cette étape est souvent appelée étape de récupération des candidats et peut également être appelée étape de génération de candidats. Les modèles de récupération se présentent sous de nombreuses formes, y compris les modèles de factorisation matricielle, les modèles à deux tours, les modèles linéaires, les modèles approximatifs du plus proche voisin et les modèles de parcours de graphe. En règle générale, les modèles de récupération sont plus efficaces en termes de calcul que les modèles de notation.
YouTube avait un excellent article en 2016 qui était l'une des premières références publiques à l'architecture, et maintenant, l'approche est largement adoptée et largement utilisée dans l'industrie. EugeneYan a un excellent article de blog sur ce sujet, et son image en deux étapes a inspiré notre graphique de recommandation en quatre étapes, qui est détaillé ci-dessous. Il convient de noter qu'il est également courant d'utiliser plusieurs sources de candidats dans le même système de recommandation pour présenter différents candidats à l'utilisateur, puis d'enregistrer ce sujet sur un autre blog.
Au-delà de la deuxième étape!
Bien qu'un modèle de recommandation à grande échelle en deux étapes puisse résoudre la plupart des problèmes, le système de recommandation doit également prendre en charge d'autres contraintes. Dans certains scénarios, l'utilisateur ne souhaite pas afficher certains éléments de données, tels que : lorsque l'élément de données n'est pas en stock, lorsque l'âge est inapproprié, lorsque l'utilisateur a déjà utilisé le contenu ou lorsque l'utilisateur n'est pas autorisé à l'afficher dans le pays, l'utilisateur Ces éléments de données ne sont pas destinés à être affichés.
En plus de s'appuyer sur des modèles de notation ou de récupération pour déduire la logique métier et recommander des éléments de données de manière appropriée, une étape de filtrage doit être ajoutée au système de recommandation. Le filtrage est généralement effectué après l'étape de récupération et peut être intégré à celle-ci (le filtrage garantit qu'il y a suffisamment de candidats après la récupération), ou même après la notation dans certains cas. La phase de filtrage applique des règles de logique métier, et sans filtrage, il serait impossible (ou du moins très difficile) pour le modèle d'appliquer des règles de logique métier. Dans certains cas, le filtrage n'est qu'une simple requête d'exclusion, mais dans d'autres, il peut être complexe, comme un filtre Bloom, qui peut être utilisé pour supprimer des éléments de données avec lesquels l'utilisateur a déjà interagi.
Trier!
Trois étapes ont été introduites jusqu'à présent : la récupération, le filtrage et la notation, qui fournissent une liste de suggestions d'éléments de données et leurs scores correspondants, qui représentent les suppositions du modèle de notation sur l'intérêt de l'utilisateur. Les résultats des recommandations sont généralement présentés aux utilisateurs sous forme de listes, ce qui présente une énigme intéressante : la liste optimale ne correspond souvent pas exactement aux scores des éléments de données. Même à l'inverse, vous souhaitez fournir aux utilisateurs un ensemble d'éléments de données complètement différent, leur montrer des éléments au-delà des candidats recommandés, explorer des espaces qu'ils n'ont jamais vus auparavant et éviter les bulles de filtre.
Dans certains ouvrages et exemples, la troisième étape des systèmes de recommandation est appelée classement, mais montrer à l'utilisateur le classement final (ou la position) de la recommandation s'aligne rarement directement sur la sortie du modèle, en fournissant une étape de classement explicite, il est possible de la sortie du modèle est alignée sur d'autres exigences ou contraintes de l'entreprise.
Système de recommandation en quatre étapes
Récupération, filtrage, notation et tri, ces quatre étapes constituent le modèle de conception du système de recommandation, qui couvre presque tous les systèmes de recommandation. Le schéma ci-dessous montre les quatre étapes et montre un exemple de la façon de construire chaque étape. Il est beaucoup plus complexe qu'un modèle de recommandation de base, surtout compte tenu du déploiement spécifique des systèmes de recommandation, et il représente avec précision la majeure partie du volume d'aujourd'hui. L'architecture de le système de recommandation.
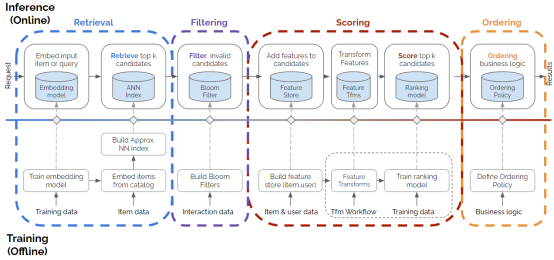
Exemple
Avec la description du modèle de système de recommandation, voyons comment créer un système de recommandation. Tout d'abord, jetez un coup d'œil à l'exemple de tâche recsys commun, qui, à un niveau élevé, couvre le cas d'utilisation en quatre phases et illustre le modèle unifié en quatre phases.
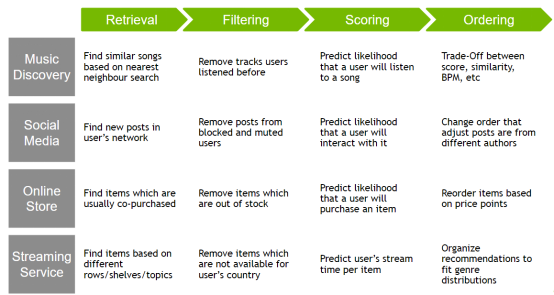
Pour aller plus loin, regardez l'exemple d'un système de recommandation réel pour voir si vous pouvez identifier quatre étapes.
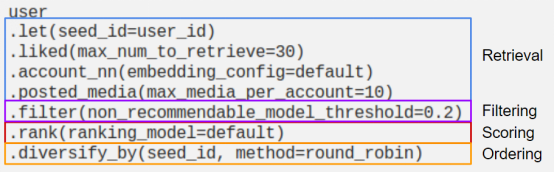
L'Instagram de Meta a un bon article sur le langage de requête qu'ils ont développé - alimenté par l'IA : une enquête sur le système de recommandation d'Instagram (langage de requête IGQL). À partir des exemples qu'ils fournissent, ce langage de requête peut être mappé avec précision dans les quatre phases du schéma de recommandation :
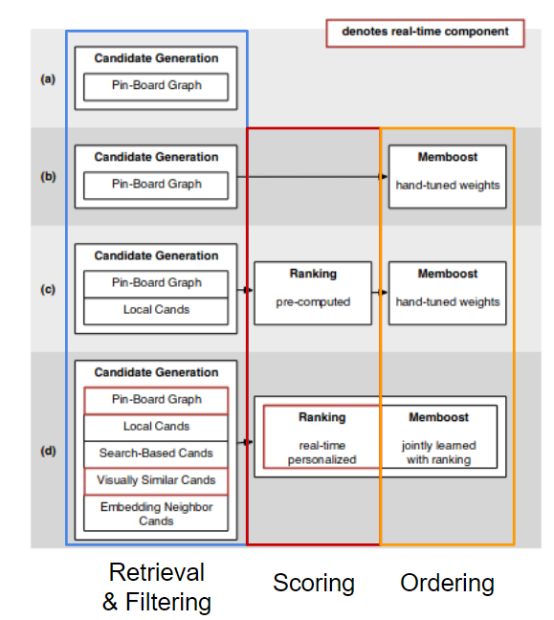
Pinterest a publié une série d'articles (contenu lié à Pinterest : évolution des systèmes de recommandation dans le monde réel, recommandation systématique de plus de 300 millions d'articles et de plus de 200 millions d'utilisateurs en temps réel, applications liées à l'apprentissage en profondeur), dont l'un est un diagramme dans le premier article. , ce qui est correct L'évolution des architectures des systèmes de recommandation dans le temps est décrite. Ici, nous reproduisons le même modèle, mais avec une différence subtile, traitant la récupération et le filtrage comme la même phase.
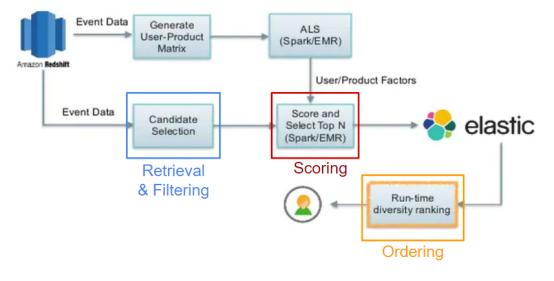
Instacart a partagé cette architecture en 2016, avec des recommandations directes à suivre en quatre étapes. Les candidats sont récupérés en premier, puis les éléments de données précédemment triés sont filtrés, les candidats les plus populaires sont notés et les résultats finaux sont reclassés pour augmenter la variété des résultats finaux présentés à l'utilisateur.
système complexe
Dans le diagramme en 4 étapes de cet article, les composants requis dans le processus de requête de temps d'inférence de la formation, du déploiement et de la prise en charge de l'étape complète sont clarifiés. Ce système est beaucoup plus complexe qu'un modèle unique, et ceux qui recherchent en ligne des informations sur le système de recommandation et ne trouvent que des modèles de filtrage collaboratifs seront dépassés lorsqu'ils essaieront de créer un système de recommandation complexe.
Dans le prochain article de blog, je vais plonger dans les détails de ce modèle complexe et proposer quelques solutions pour le cadre du système de recommandation Merlin. Maintenant, je vous laisse le défi : interpréter et utiliser le système de recommandation en détail, pouvez-vous identifier les quatre étapes ? , et si oui Non, vous pouvez également communiquer avec nous ! Nous continuerons à itérer et à améliorer nos idées et nos bibliothèques, en nous efforçant de fournir la meilleure solution pour l'espace RecSys, et nous apprécions grandement votre contribution.
Enfin, si vous souhaitez créer des bibliothèques open source pour simplifier la construction et le déploiement de systèmes de recommandation, n'hésitez pas à communiquer avec vous.
Titre original:
Des systèmes de recommandation, pas seulement des modèles de recommandation
Lien d'origine :