À l'ère de l'intelligence artificielle, la mesure ultime du succès d'un produit d'IA est de savoir dans quelle mesure il peut améliorer l'efficacité de nos vies. À mesure que la technologie de l'IA passera du cloud à la périphérie, les problèmes d'ingénierie qui doivent être optimisés deviendront plus complexes. Une évaluation efficace avant la conception de la puce devient de plus en plus importante pour le succès final du produit. Cependant, en raison de la nature complexe des scénarios d'application des puces IA, l'industrie a besoin d'outils d'évaluation corrects et professionnels.
L'une des énigmes de l'industrie de l'IA :
Les puces IA ne peuvent pas suivre la vitesse des algorithmes
Dès 2019, l'Université de Stanford a signalé que la vitesse de la demande de puissance de calcul de l'IA est plus rapide que la vitesse de développement des puces. "Avant 2012, le développement de l'IA suivait de très près la loi de Moore, et la puissance de calcul doublait tous les deux ans, mais après 2012, la puissance de calcul de l'IA doublait tous les 3,4 mois."
Lorsque la puissance de calcul des processeurs à usage général ne peut pas répondre aux besoins des applications d'IA, des processeurs dédiés au calcul de l'IA voient le jour, souvent appelés "puces d'IA". Depuis 2015, les algorithmes d'IA ont dépassé les scores humains en matière de reconnaissance visuelle, et l'industrie a accordé plus d'attention aux puces d'IA, ce qui a également entraîné le développement de technologies IP connexes, accéléré la vitesse des processeurs et des mémoires de nouvelle génération et atteint une bande passante plus élevée. interfaces. , afin de suivre le rythme des algorithmes d'IA. La figure 1 montre la réduction visible des taux d'erreur typiques de l'IA depuis l'introduction de la rétropropagation et des réseaux de neurones modernes en 2012, combinés au moteur GPU de calcul intensif de NVIDIA.
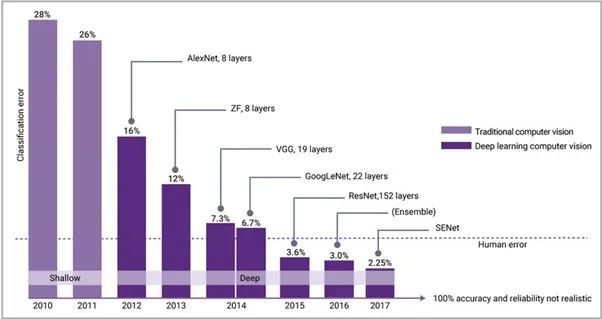
Figure 1 : Après l'introduction des réseaux de neurones modernes en 2012, les erreurs de classification de l'IA ont rapidement diminué, ce qui est inférieur aux taux d'erreur humaine depuis 2015
Comme les algorithmes d'IA deviennent plus complexes et ne peuvent pas être exécutés sur des SoC conçus pour les produits grand public, ils doivent être compressés à l'aide d'élagage, de quantification et d'autres techniques pour aligner et compresser, réduisant ainsi la quantité de mémoire et de calcul requise par le système, mais au dépens de la précision. Il y a donc un défi d'ingénierie : comment mettre en œuvre des techniques de compression sans compromettre la précision requise pour les applications d'IA ?
Outre la complexité croissante des algorithmes d'IA, la quantité de données requises pour l'inférence a considérablement augmenté en raison de l'augmentation des données d'entrée. La figure 2 montre la mémoire et le calcul requis pour l'algorithme de vision optimisé. L'algorithme est conçu pour avoir une empreinte mémoire relativement petite de 6 Mo (exigence de mémoire de SSD-MobileNet-V1). Dans cet exemple particulier, nous pouvons voir que la mémoire requise dans la dernière capture d'image est passée de 5 Mo à plus de 400 Mo à mesure que la taille des pixels et la profondeur de couleur ont augmenté.
Actuellement, le dernier appareil photo à capteur d'image CMOS pour téléphone portable Samsung prend en charge jusqu'à 108MP. En théorie, ces caméras pourraient nécessiter 40 TOPS de performances à 30 ips et plus de 1,3 Go de RAM. Cependant, la technologie du FAI et le domaine spécifique de l'algorithme AI ne peuvent pas répondre à ces exigences, et les performances 40 TOPS ne peuvent pas être réalisées sur le téléphone mobile. Mais cet exemple montre la complexité et les défis des dispositifs de pointe et est également à l'origine de l'évolution de l'interface IP des capteurs. MIPI CSI-2 dispose d'une zone dédiée pour résoudre ce problème, et MIPI C/D-PHY continue d'augmenter la bande passante pour gérer les dernières données de capteur d'image CMOS pilotant des centaines de millions de pixels.
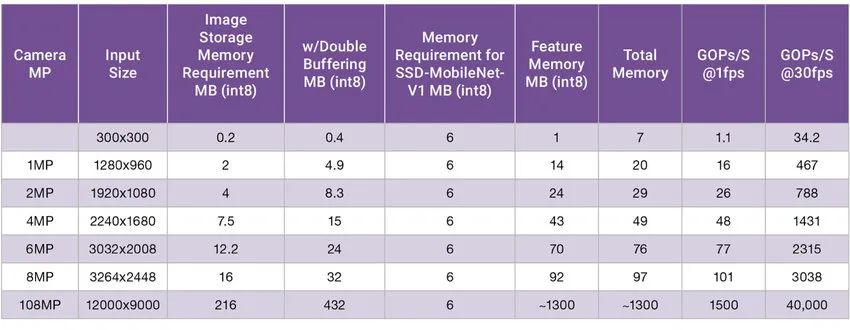
Figure 2 : Test de changement de mémoire de SSD-MobileNet-V1 à mesure que les pixels d'entrée augmentent
La solution d'aujourd'hui consiste à compresser les algorithmes d'IA, compresser les images, ce qui rend l'optimisation des puces extrêmement complexe, en particulier pour les SoC à mémoire limitée, capacité de traitement limitée et petits budgets de puissance.
Problème 2 de l'industrie de l'IA : l'évaluation des puces d'IA est confrontée à des défis
Les fabricants de puces IA effectuent généralement une analyse comparative de leurs puces. Il existe aujourd'hui de nombreuses métriques différentes pour les SoC. Premièrement, le billion d'opérations par seconde (TOPS) est un indicateur principal de performance, et ces données fournissent une image plus claire des capacités de la puce, telles que le type et la qualité des opérations que la puce peut gérer. Encore une fois, les inférences par seconde sont une mesure principale, mais la fréquence et d'autres paramètres doivent être compris. Par conséquent, des références supplémentaires ont été développées dans l'industrie pour aider à évaluer les puces IA.
MLPerf/ML Commons et AI.benchmark.com sont des outils d'analyse comparative standardisée des puces IA. Parmi eux, ML Commons fournit principalement des règles de mesure liées à la précision, à la vitesse et à l'efficacité de la puce, qui sont très importantes pour comprendre la capacité de la puce à traiter différents algorithmes d'IA.Il existe un compromis entre le degré de compression. De plus, ML Commons fournit des ensembles de données communs et les meilleures pratiques.
Le laboratoire de vision par ordinateur de Zurich, en Suisse, fournit également des références pour les processeurs mobiles et publie leurs résultats, les exigences en matière de silicium et d'autres informations pour favoriser la réutilisation. Comprend 78 tests et plus de 180 tests de performance.
DAWNBench de l'Université de Stanford a apporté son soutien aux travaux sur ML Commons. Ces tests portent non seulement sur la notation des performances de l'IA, mais également sur le temps total nécessaire à un processeur pour effectuer la formation et l'inférence de l'algorithme d'IA. Cela répond à un problème clé des objectifs d'ingénierie de conception de puces, qui est de réduire le coût total de possession, ou le coût total de possession. Le temps de traitement de l'IA, qui détermine la propriété de la puce pour la location d'IA dans le cloud ou l'informatique de pointe, est plus utile pour la stratégie globale de puce IA d'une organisation.
Une autre méthode d'analyse comparative populaire consiste à utiliser des graphiques et des modèles open source communs, mais ces modèles présentent également certains inconvénients. Par exemple, le jeu de données ResNET-50 est de 256x256, mais ce n'est pas nécessairement la résolution qui pourrait être utilisée dans l'application finale. Deuxièmement, le modèle est plus ancien et comporte moins de couches que de nombreux modèles plus récents. Troisièmement, le modèle peut être optimisé manuellement par le fournisseur IP du processeur, mais cela ne représente pas la façon dont le système fonctionnera avec d'autres modèles. En plus de ResNET-50, il existe un grand nombre de modèles open source disponibles à travers lesquels les avancées récentes dans le domaine peuvent être vues et fournir de bonnes mesures de performance.
Enfin, les graphiques et modèles personnalisés pour des applications spécifiques sont de plus en plus courants. Idéalement, c'est le meilleur moyen de comparer une puce AI et de l'optimiser correctement pour réduire la consommation d'énergie et améliorer les performances.
Étant donné que les développeurs de SoC ont des objectifs différents, certains concernent des applications hautes performances, d'autres des domaines moins performants, d'autres des IA générales et d'autres des ASIC. Pour les SoC qui ne savent pas par quel modèle d'IA ils doivent optimiser, un bon mélange de modèles personnalisés et de modèles librement disponibles est un bon indicateur de performances et de consommation d'énergie. Cette combinaison est la plus couramment utilisée sur le marché aujourd'hui. Cependant, l'émergence des nouvelles normes d'analyse comparative mentionnées ci-dessus semble être quelque peu pertinente dans les comparaisons après l'entrée des SoC sur le marché.
L'évaluation avant la conception de la puce AI de pointe est particulièrement importante
De plus en plus de calcul de données se produit désormais à la périphérie, et compte tenu de la complexité de l'optimisation de la périphérie, les solutions d'IA d'aujourd'hui doivent co-concevoir des logiciels et du silicium. Pour ce faire, ils doivent utiliser les bonnes techniques d'analyse comparative et doivent être soutenus par des outils qui permettent aux concepteurs d'explorer avec précision différentes manières d'optimiser un système, un SoC ou une IP à semi-conducteurs, en étudiant les nœuds de processus, les mémoires, les processeurs, les interfaces, etc.
À cet égard, Synopsys fournit des outils spécifiques au domaine pour la simulation, le prototypage et l'analyse comparative des IP, des SoC et des systèmes plus larges.
Premièrement, les solutions de prototypage Synopsys HAPS® sont souvent utilisées pour démontrer les capacités et les compromis des différentes configurations de processeur. L'outil est-il capable de détecter quand, en plus du processeur, la bande passante d'un système d'IA commence à devenir un goulot d'étranglement ? Quelle est la bande passante optimale pour l'entrée du capteur (via MIPI) ou l'accès à la mémoire (via LPDDR) pour différentes tâches ?
Encore une fois, le système de simulation Synopsys ZeBu® peut être utilisé pour la simulation de puissance. ZeBu Empower peut prendre en charge de véritables charges de travail logicielles pour l'IA, la 5G, les centres de données et les applications SoC mobiles et effectuer des cycles de vérification de l'alimentation en quelques heures. Il a été démontré que ce système de simulation surpasse la simulation et/ou l'analyse statique des charges de travail d'IA.
Les utilisateurs peuvent également explorer le niveau système des conceptions de SoC via l'architecte de plate-forme de Synopsys. Utilisé à l'origine pour la mémoire, les performances de traitement et l'exploration de l'alimentation, Platform Architect est de plus en plus utilisé pour comprendre les performances au niveau du système et la consommation d'énergie pour l'IA. À l'aide de LPDDR prédéfinis, de modèles de processeur ARC pour l'IA, la mémoire, etc., une analyse de sensibilité peut être effectuée pour déterminer les paramètres de conception optimaux.
Synopsys dispose d'une équipe expérimentée qui développe des solutions de traitement d'IA allant du concepteur ASIP aux processeurs ARC. Un portefeuille éprouvé d'IP de base, y compris des compilateurs de mémoire, est largement utilisé dans les SoC IA. L'interface IP pour les applications d'IA va des entrées de capteur à I3C et MIPI, à la connectivité puce à puce via les solutions CXL, PCIe et Die to Die, et aux capacités de mise en réseau via Ethernet.
Résumer
La co-conception de logiciels et de silicium est devenue une réalité, et le choix des bons outils et de l'expertise est essentiel. Synopsys s'appuie sur son expertise, ses services et sa propriété intellectuelle éprouvée pour fournir aux clients l'approche la mieux adaptée pour optimiser les puces IA dans des circonstances changeantes.
auteur de cet article
Ron Lowman, directeur du marketing stratégique IP, Synopsys
* Avis de non-responsabilité : cet article a été écrit à l'origine par l'auteur. Le contenu de l'article est l'opinion personnelle de l'auteur. La réimpression de Semiconductor Industry Observation n'a pour but que de transmettre un point de vue différent. Cela ne signifie pas que Semiconductor Industry Observation est d'accord ou soutient le point de vue. Si vous avez des objections, veuillez contacter Semiconductor Observation de l'industrie.
Aujourd'hui, c'est le 3120e contenu partagé par "Semiconductor Industry Watch" pour vous, bienvenue à faire attention.
Lecture recommandée
★ Les semi-conducteurs de puissance du Japon, une autre longueur d'avance
★ La valeur marchande d'AMD dépasse celle d'Intel, le début d'une nouvelle ère
★ Le "bureau central" de Biden
Veille de l'industrie des semi-conducteurs

« Premier média vertical semi -conducteur »
Profondeur originale professionnelle en temps réel
Identifiez le code QR , répondez aux mots-clés suivants, en savoir plus
Wafer|Circuits intégrés|Dispositifs|Puces automobiles|Stockage|TSMC|AI|Emballage
Répondre Contribution , voir "Comment devenir membre de "Semiconductor Industry Watch""
Répondez à la recherche et vous pourrez facilement trouver d'autres articles qui vous intéressent !